
| | The differing business objectives of information technology (IT) and operational technology (OT) have caused a cultural distinction within the typical industrial setting. This separation has prohibited the technology available within each area to symbiotically exist. In some instances, a handful of parameters may be exchanged between the two areas. This information is used by organizations to determine how to effectively produce the highest-quality products at maximum profitability. This includes maximizing the utilization of the assets used throughout the production cycle. Being able to understand current operating conditions and identify the root cause to common failure conditions is limited to human interaction and analysis.
In today’s manufacturing environment, an overwhelming amount of data is being produced, processed and pushed by various operational technology (OT) systems to information technology (IT) systems. This influx is beginning to overwhelm the capacity of the latter. The traditional data center faces challenges due to an insufficient network that lacks the bandwidth to transfer and process the immense amount of information being produced by emerging process automation technologies. DEFINITION To ease this burden, and to enhance the overall end-user experience, an entirely new area has emerged to bridge the gap between the systems at the information technology and the operation technology layers. This new arena is often referred to as the “edge.” Edge devices not only transfer this data but are also used to process the data as needed for retention, analytic and security purposes. This allows data to be filtered, aggregated and encrypted within each layer as well as the layer it was generated. Process knowledge can be effectively injected to create useful information.
EDGE ANALYTICS
Edge analytics, or edge computing, is an approach to data collection and analysis in which an automated analytical computation is performed on data at a sensor, network switch or other device instead of waiting for the data to be sent back to a centralized data store. This functionality enables users to begin to bridge the gap between the IT and OT layers that exist within an enterprise. The data produced by the process automation layer can be leveraged in applications that require low-latency feedback. In addition, by providing a filtering mechanism, the same data can be effectively transferred to a centralized data center or to the cloud. HISTORY Historically speaking, industrial automation specialists followed a design architecture derived from The Purdue Enterprise Reference Architecture and Methodology (PERA).1 In a traditional steel producer’s information transfer model, stepwise aggregation is done between the various layers. The raw data from physical sensors are primarily used to control the process (level 1 or L1). Process and quality parameters are then calculated and sent to the process automation layer (level 3 or L2). These aggregates are then combined with other manufacturing characteristics and supplied to management level systems (level 3 or L3). The information is then able to be converted into actionable information such as overall equipment effectiveness (OEE) and key performance indicators (KPIs) as shown in Fig. 1. Historically speaking, industrial automation specialists followed a design architecture derived from The Purdue Enterprise Reference Architecture and Methodology (PERA).1 In a traditional steel producer’s information transfer model, stepwise aggregation is done between the various layers. The raw data from physical sensors are primarily used to control the process (level 1 or L1). Process and quality parameters are then calculated and sent to the process automation layer (level 3 or L2). These aggregates are then combined with other manufacturing characteristics and supplied to management level systems (level 3 or L3). The information is then able to be converted into actionable information such as overall equipment effectiveness (OEE) and key performance indicators (KPIs) as shown in Fig. 1.
There are several issues present with this model that can be alleviated with a successful digitization strategy. The fixed calculations and data transfer need to be programmed between each layer. At each layer a unique set of skills, along with time and resources, is required to implement the appropriate aggregation techniques. Any modifications require an additional allotment of time and resources as well. If data is to be present at one of the layers outside of its origin, there are challenges in providing accurate and precise traceability. The ability to drill down in order to gain access to the original source signal or raw data is not possible.
 Implementing a holistic approach from data to information allows for greater flexibility, traceability and transparency when troubleshooting. The time and resources once needed to add or modify the transfer of information between the layers is drastically reduced. The time synchronization and structured archiving of all data is done as close to the origin as possible. This enables the calculation of KPIs based on the raw data. The origin of the data used is known, traceable and can be easily verified by the various stakeholders accessing the information. A sufficient edge platform enables the ability to compress and encrypt the data provided to a centralized data center or to the cloud as well as provide the traceability to drill down from aggregated information to raw data as demonstrated in Fig. 2. Implementing a holistic approach from data to information allows for greater flexibility, traceability and transparency when troubleshooting. The time and resources once needed to add or modify the transfer of information between the layers is drastically reduced. The time synchronization and structured archiving of all data is done as close to the origin as possible. This enables the calculation of KPIs based on the raw data. The origin of the data used is known, traceable and can be easily verified by the various stakeholders accessing the information. A sufficient edge platform enables the ability to compress and encrypt the data provided to a centralized data center or to the cloud as well as provide the traceability to drill down from aggregated information to raw data as demonstrated in Fig. 2.
TECHNOLOGIES
The use of computers is not the center of digital transformation, but rather the intelligent networking of internet-capable sensors and devices to efficiently transfer information. The ability to access copious amounts of data from the factory floor has become readily available for all the stakeholders within the manufacturing process. This accessibility is driving the technological advances necessary to effectively translate and process this data into actionable insights automatically at the various layers in which they occur. Technological advancements in the effectiveness of cost-efficient computing resources continue to drive the adoption of Industrial Internet of Things devices communicating to cloud platforms via an edge analytics layer. EXAMPLE APPLICATIONSMACHINE LEARNING AT THE EDGE FOR COIL TRACKING VERIFICATION
A common challenge facing many top steel-producing companies exists in the supply chain of flat products. The production cycle is a multi-step process that consists of several individual steps decoupled by storage and transportation routes. Even with advanced material tracking systems, an inherent risk exists in selecting the wrong coil when transferring from one location to the next. A method was developed in which a unique digital fingerprint is assigned to each product as it leaves each of the process stages. This method is based on mathematical methods for analyzing time series data with the assumption that there is no significant material deformation between the two process areas. In cooperation with research institutes, proprietary algorithms were developed leveraging machine-learning techniques to describe a coil by its so-called features.2
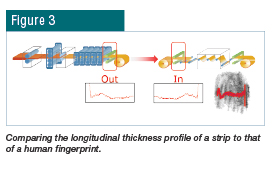
By analyzing a unique and inherent property of the coil rather than an external marker, for instance the longitudinal thickness profile, a reliable measurable parameter can be used to verify its identity. This can be easily imagined as being similar to a human fingerprint, as shown in Fig. 3. Due to the low-latency requirement of the application, a cloud-based computational approach to this implementation is neither practical nor efficient. In order to effectively identify a mismatched coil so it can be blocked from continuing through the process as soon as possible before further time and resources are spent, an edge computing layer was implemented. Utilizing an efficient digitalization strategy, these calculations along with their results can exist within devices on the edge for low-latency feedback as well as for providing aggregate length-based product quality parameters to cloud-based business systems.
 SUMMARYDigitalization will continue to drive technological advancements for predictive maintenance, machine learning and visual aid technologies. A critical factor in the success of each one of these technologies is the real-time feedback to the industrial automation systems. In addition to the feedback for operators, the ability of edge devices to perform analytics allows for automated, data-driven decision-making. Functionally, the facilities’ operational technology passes data northbound to the edge devices. These edge devices can pass information northbound to a data center or a cloud for advanced analytical processing. However, the latency introduced by involving these information technologies systems does not enable real-time feedback southbound. Rather than waiting for data to be sent to a centralized data store, data analytics can be performed directly at the device and automatically processed into actionable information. This is where the power of these edge devices comes to fruition.
With the growing computational capabilities of edge devices, along with the continuous optimization of software technologies, the ability to access helpful data at each stage of the manufacturing process can be used to streamline processes, maximize productivity and minimize the amount of resources used.
REFERENCES - T. Williams, “The Purdue Enterprise Reference Architecture and Methodology (PERA),” Institute for Interdisciplinary Engineering Studies Purdue University, 1992.
- H. Anhaus, “Method and Device for Identifying a Section of a Semi-Finished Product, German Patent DE 10 2006 006 733 B32007.08.23 (in German).
|
